early thoughts & experiments on generative ai

FinanceGPT
This week, I made a quick website where you can query financial records of a publicly traded company, in natural language and get an accurate response. We made this as part of Quark Code by the Beach Hackathon in <30 hours. [try it out here]

brief on how it works?
If you directly ask ChatGPT any such question it is not going to be able to answer the question, and if it does, it will hallucinate random numbers. So how can we approach this?
We already know that ChatGPT is quite good at answering questions as a conversation, it just doesn’t know what to answer. So what if we give it a context of the relevant information and ask it to answer absolutely just based on that information provided. This raises the question of what question to provide? All publicly listed companies publish their annual reports which are easily accessible, and we just have to figure out a way to give ChatGPT the write context. This can be achieved in better way using Semantic Search.
Semantic Search
Let’s say you want to ask it about what was the amount of coal that passed through all ports operated by Adani Ports. If you just search the keywords in annual report,
i. the results contain just too many references to coal
ii. the types of coal that the ports can handle
A simple search would return (most times) irrelevant and broad results.
Or for example, if you were looking games with the name “Star Wars: Battlefront”, a normal search could only find you results that match exactly that phrase. However, a semantic search could find you other games in the same genre or with similar themes. For example, it could find you “StarCraft: Legacy of the Void” or “Halo: Combat Evolved”. This type of search helps identify related items that may not have been known or expected, improving the accuracy and speed of the search.
So how to address it? Basically we can convert all reference text as vectors in a space. The way these vectors will be given their values depending on how similar they are, how similar the context where it is present is, etc. Now whenever we get a query, we can convert that query to a vector in that same space, and figure out the which vectors are closest to that vector. And this would give us the closest set of texts that could answer the query the user asks.
How do embeddings work?
Embeddings compress discrete information (words & symbols) into distributed continuous-valued data (vectors). If we took some phrases from and plot them on a chart, it might look something like this:
source: https://supabase.com/blog/openai-embeddings-postgres-vector
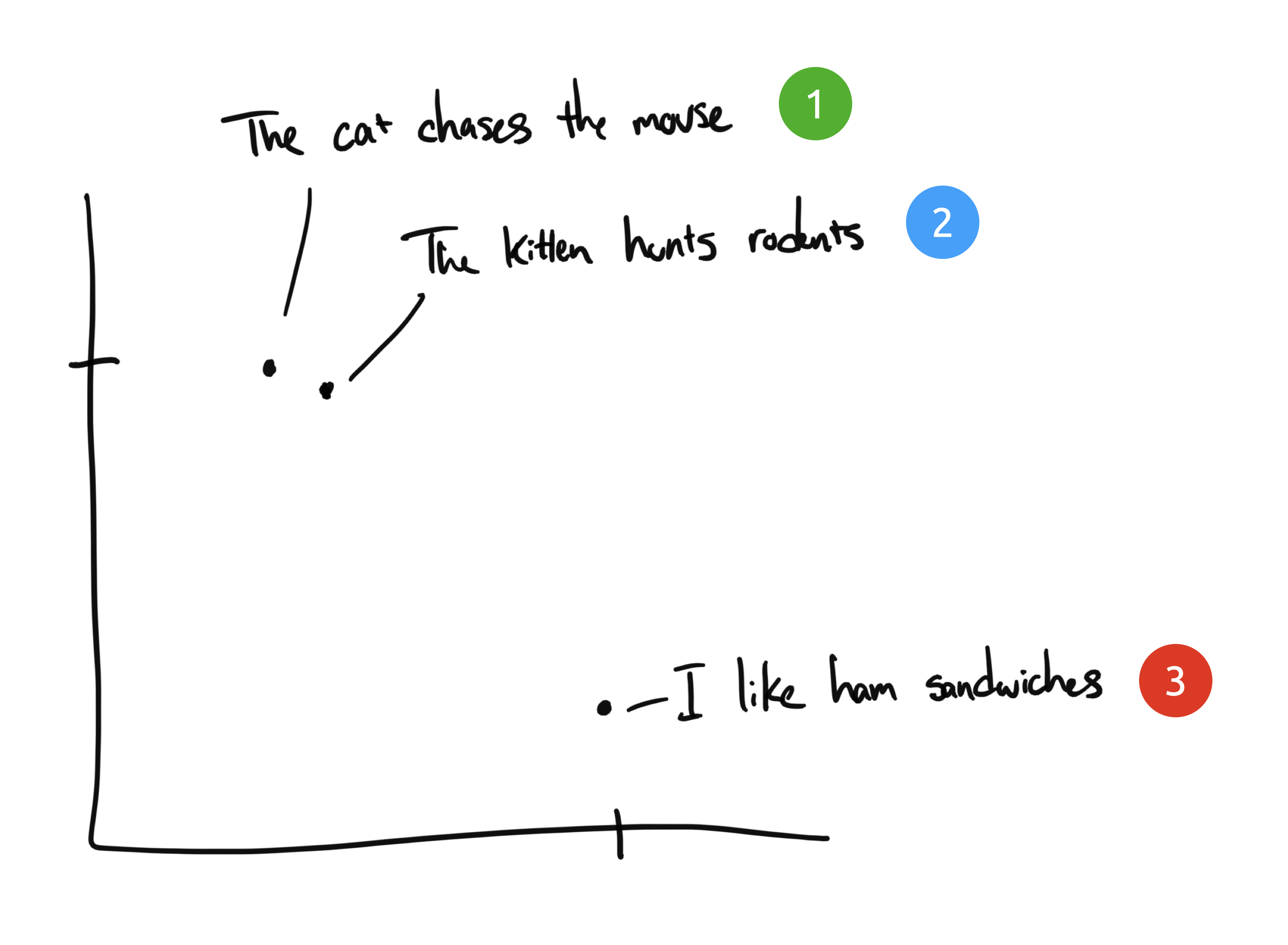
Now after taking out the similar parts, we query ChatGPT to answer the question precisely and in natural language. I won’t go into much more details, but wanted to share the part about semantic search as I found that fascinating. You can look at GitHub Repo for more info.
Interesting Things
Here is a collection of projects / ideas I found interesting this week:
-
On GPT4: A lot of people say that LLMs are nothing but text prediction; which I think is fair. but..
”it means that you understand the underlying reality that led to the creation of that token” (@ilyasut) -
Google research released a new model for visual identification from images (screenshots specifically) and its apparently really good at solving captchas. (try it out here)
Advancements like this and with text being produced by GPT4 (being so much better than humans) it is and will be getting difficult to differentiate humans from bots. It will be almost as if that without data & fingerprinting techniques by those of Google / Cloudflare it will be impossible to determine human / not.
-
You can download specific folders from Github (not directly)
-
Run ChatGPT-like models locally on your CPU
-
Run Deep Learning models in your browser (based on WASM)
🤯🤯🤯
Bicycle by Bartosz Ciechanowski
Matt Henderson @matthen2 to tell if a maze is solvable, just hang it by its corners! The first maze stays in one piece, so there is no path from the entrance at the top to the exit at the bottom. The second maze splits apart along the solution.
Georgi Gerganov @ggerganov Announcing the Local LLaMA podcast 🎙️🦙 In today’s episode we have LLaMA, GGaMA, SSaMA and RRaMA joining us to discuss the future of AI